

SQL Data Cleansing and Analysis project
How can we take raw redundancy data and transform it in SQL Server to enable analysis of trends and drivers?
Data cleaning
Data cleaning is the first step where we take the raw data and fix a lot of the issues with the format of the data and make it more suitable for visualizations and analysis.
The first step is to import the data into MySQL Workbench. This is done by creating a new database (schema) and then import table data.
To view the data in the table:
SELECT *
FROM layoffs;To work on this data, we want to create a copy of the data so that we keep an original set of the raw data we can go back to.
CREATE TABLE layoffs_staging
LIKE layoffs;INSERT layoffs_staging
SELECT *
FROM layoffs;The steps of data cleansing (on the “layoffs_staging” table) will then be:
— 1. Remove Duplicates
— 2. Standardize Data
— 3. Null Values or blank values
— 4. Remove any columns or rows
Removing Duplicates
We will now be looking for any duplicate data and removing it from the table.
The first setup is to insert a row id to the data in order to aid the removal of any duplicates.
SELECT *,
ROW_NUMBER() OVER(
PARTITION BY company, industry, total_laid_off, percentage_laid_off, `date`) AS row_num
FROM layoffs_staging;
WITH duplicate_cte AS
(
SELECT *,
ROW_NUMBER() OVER(
PARTITION BY company, location, industry, total_laid_off, percentage_laid_off, `date`, stage, country, funds_raised_millions) AS row_num
FROM layoffs_staging
)
SELECT *
FROM duplicate_cte
WHERE row_num > 1;We can then run this query and change the company name to investigate the duplicates
SELECT *
FROM layoffs_staging
WHERE company = 'Casper';Then to remove the duplicates, we first create a new table (a staging 2 database) which includes row number.
CREATE TABLE `layoffs_staging2` (
`company` text,
`location` text,
`industry` text,
`total_laid_off` int DEFAULT NULL,
`percentage_laid_off` text,
`date` text,
`stage` text,
`country` text,
`funds_raised_millions` int DEFAULT NULL,
`row_num` INT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
SELECT *
FROM layoffs_staging2;
INSERT INTO layoffs_staging2
SELECT *,
ROW_NUMBER() OVER(
PARTITION BY company, location, industry, total_laid_off, percentage_laid_off, `date`, stage, country, funds_raised_millions) AS row_num
FROM layoffs_staging;We can then filter on row numbers greater than 1 (the duplicates!)
SELECT *
FROM layoffs_staging2
WHERE row_num > 1;and Delete them:
DELETE
FROM layoffs_staging2
WHERE row_num > 1;Standardizing Data
Next is to make sure that each column contains standard format of data throughout.
For example we can trim spaces off the start and end of entries (white spaces).
SELECT company, TRIM(company)
FROM layoffs_staging2;
UPDATE layoffs_staging2
SET company = TRIM(company);Then look at the industry and look at blanks or slightly different versions of the same industry
SELECT DISTINCT industry
FROM layoffs_staging2
ORDER BY 1;e.g Crypto / Crypto Currency):
SELECT *
FROM layoffs_staging2
WHERE industry LIKE 'Crypto%';
UPDATE layoffs_staging2
SET industry = 'Crypto'
WHERE industry LIKE 'Crypto%';Then check it worked:
ELECT *
FROM layoffs_staging2
WHERE industry LIKE 'Crypto%';Repeat the process or any other issues with format.
For example “Country”:
SELECT DISTINCT country
FROM layoffs_staging2
ORDER BY 1;Need to remove United States.
SELECT DISTINCT country, TRIM(TRAILING '.' FROM country)
FROM layoffs_staging2
ORDER BY 1;
UPDATE layoffs_staging2
SET country = TRIM(TRAILING '.' FROM country)
WHERE country LIKE 'United States%';And then date format setting of the column (change from text to date format):
SELECT `date`,
str_to_date(`date`, '%m/%d/%Y')
FROM layoffs_staging2
;
UPDATE layoffs_staging2
SET `date` = str_to_date(`date`, '%m/%d/%Y')
;
ALTER TABLE layoffs_staging2
MODIFY COLUMN `date` DATE;Null Values or blank values
Remove null or black values. First try and populate by looking at similar rows (same industry)
SELECT *
FROM layoffs_staging2
WHERE industry is NULL
OR industry = '';An example is Airbnb:
SELECT *
FROM layoffs_staging2
WHERE company = 'Airbnb';Identify and Update the values by using a JOIN:
SELECT *
FROM layoffs_staging2 t1
Join layoffs_staging2 t2
ON t1.company = t2.company
WHERE (t1.industry IS NULL OR t1.industry = '')
AND t2.industry IS NOT NULL;
UPDATE layoffs_staging2 t1
Join layoffs_staging2 t2
ON t1.company = t2.company
SET t1.industry = t2.industry
WHERE t1.industry IS NULL
AND t2.industry IS NOT NULL;Removing rows where two columns are null
SELECT *
FROM layoffs_staging2
WHERE total_laid_off is NULL
AND percentage_laid_off is NULL;
DELETE
FROM layoffs_staging2
WHERE total_laid_off is NULL
AND percentage_laid_off is NULL;Remove any columns or rows
Removing the row number column:
SELECT *
FROM layoffs_staging2;
ALTER TABLE layoffs_staging2
DROP column row_num;Analysis of Data

Here are a few ways we can use SQL to manipulate the data to find trends or snapshots. Otherwise known as Exploratory Data Analysis!
Lets bring up the cleaned data:
Select *
From layoffs_staging2;Can we see what was the maximum number of layoffs in one day?
elect MAX(total_laid_off), MAX(percentage_laid_off)
From layoffs_staging2;
This means that 100% of the company was laid off which totaled 12,000 jobs.
What other companies have laid off all employees (ordered by largest first)?
Select *
From layoffs_staging2
WHERE percentage_laid_off = 1
ORDER BY total_laid_off DESC;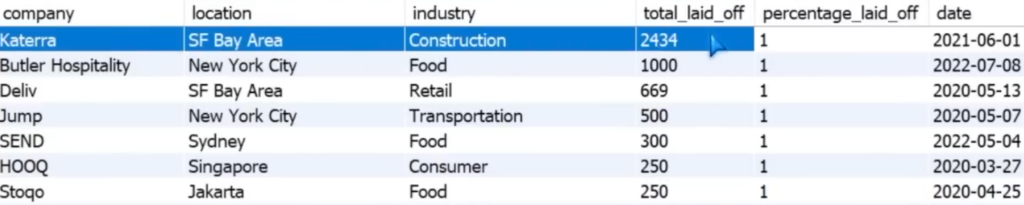
Or we could look at ordering it by the most funds raised:
Select *
From layoffs_staging2
WHERE percentage_laid_off = 1
ORDER BY funds_raised_millions
DESC;
We could group the company by the sum of laid off:
Select company, sum(total_laid_off)
From layoffs_staging2
GROUP BY company
ORDER BY 2 desc;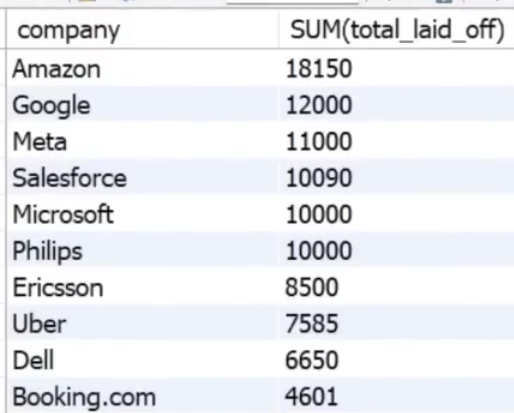
We can check the date range for the data:
SELECT MIN(`date`),MAX(`date`)
From layoffs_staging2;
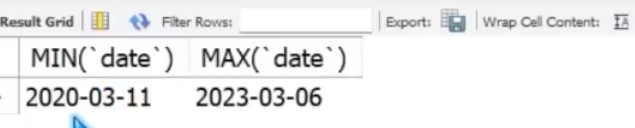
This shows that the data covers 3 years from around the outbreak of Covid 19.
We can see which industries suffered most during this time:
Select industry, sum(total_laid_off)
From layoffs_staging2
GROUP BY industry
ORDER BY 2 desc;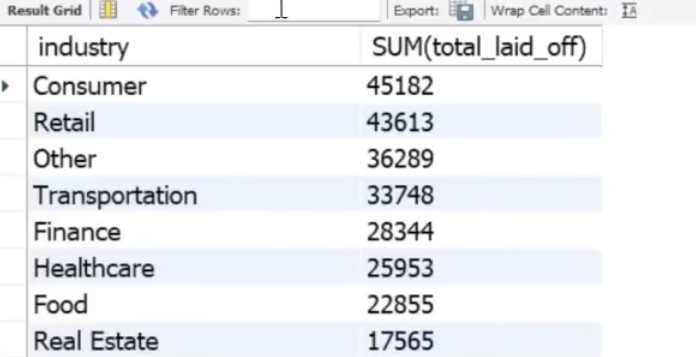
Not really surprising that consumer and retail would be worst effected due to the lockdowns.
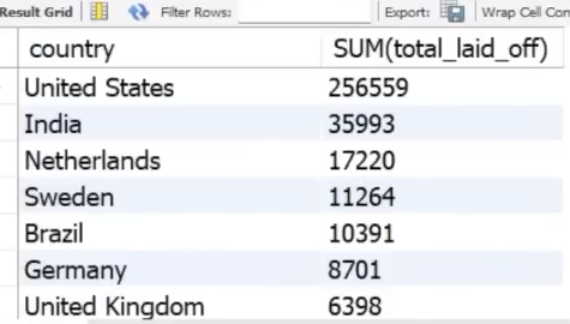
Which countries had the most layoffs?
Select country, sum(total_laid_off)
From layoffs_staging2
GROUP BY country
ORDER BY 2 desc;
How were the numbers grouped by year?
Select YEAR(`date`), sum(total_laid_off)
From layoffs_staging2
GROUP BY YEAR(`date`)
ORDER BY 1 desc;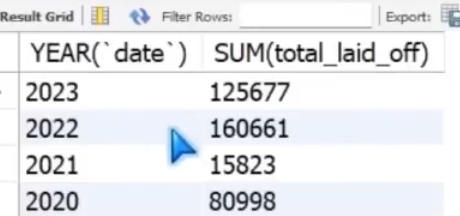
It should be noted that 2023 is only 3 months of data!
We can do a rolling sum of layoffs until the end of the data period:
WITH Rolling_Total AS
(
SELECT SUBSTRING(`date`,1,7) AS `MONTH`, SUM(total_laid_off) AS total_off
From layoffs_staging2
WHERE SUBSTRING(`date`,1,7) IS NOT NULL
GROUP BY `MONTH`
ORDER BY 1 ASC
)
SELECT `MONTH`, total_off,
SUM(total_off) OVER(ORDER BY `MONTH`) AS rolling_total
FROM Rolling_Total
;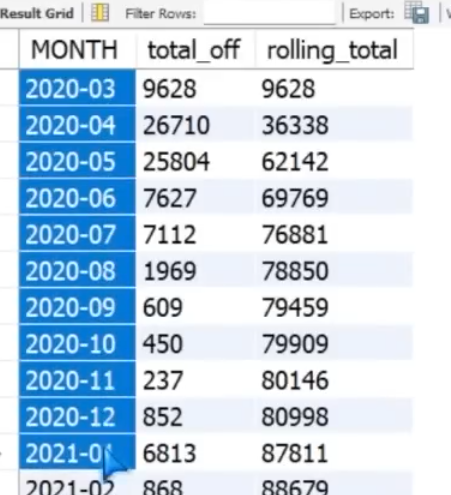
We can now see how the numbers built up by month over the period.
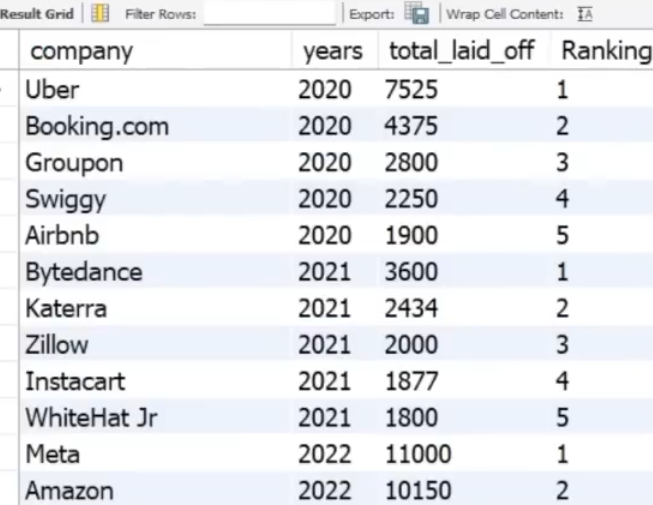
Lets look at it by company by year, then rank each year as a top 5:
WITH Company_Year (company, years, total_laid_off) AS
(
Select company, YEAR(`date`), sum(total_laid_off)
From layoffs_staging2
GROUP BY company, YEAR(`date`)
), Company_Year_Rank AS
(SELECT *, DENSE_RANK() OVER (PARTITION BY years ORDER BY total_laid_off DESC) AS Ranking
FROM Company_Year
WHERE years IS NOT Null
)
SELECT *
FROM Company_Year_Rank
WHERE ranking <= 5
;
There you have some examples of how you can use SQL queries to dive in an analyse data. This is just a start and there are many more ways of digging into and presenting the results!